数据的分组查询(Group)与排序查询(Order)
前面我们所学习的内容,绝大多数都是针对单条的数据记录与关系型数据展开工作,而在本文之中,我们将就数据的分组查询与排序查询展开讨论,他们是“集群作战”,是围绕数据集合的一系列工作,对于我们的数据管理工作而言,具有很大意义。
应用商店程序在如今的 Linux 上是一项非常普及的服务,它可以帮助我们很快地搜索到我们期待的应用程序(无论是编程软件,游戏,还是其它的什么东西)。

(FlatHub 应用商店程序截图)
而诸多的应用商店程序遵循的原理,实际上非常简单,他们首先将会按照某种方式,将存储于远程服务器(这就是我们很多时候提到的 “dnf 源”,“apt 源”)上面的应用程序记录列表加以返回(因为登记于应用商店的程序,往往很多,因此查询的,常常只是一个子集),并按照用户的指示,下载对应的应用程序到本地计算机上,加以安装。

(应用程序商店程序的一种原理简介)
而以此为切入口,可以很好地帮助我们理解分组查询与排序查询的作用。
GROUP BY 语句简介
假定我们正在设计一款新的应用�商店程序,为数据库程序配置了如下的数据表:
CREATE TYPE APPLICATION_TYPE AS ENUM ('beta', 'alpha', 'release', 'production');
/* 用一张数据表描述应用程序列表 */
CREATE TABLE application_list (
name TEXT, /* 应用程序名称 */
author TEXT, /* 用于描述应用程序的作者 */
description TEXT, /* 用于描述应用程序的作用 */
logo_url TEXT, /* 用于存储应用程序 LOGO 的 URL */
theme_color TEXT, /* 用于存储应用程序的主题色 */
publish_date DATE, /* 用于描述应用程序的发版日期 */
type APPLICATION_TYPE, /* 用于描述应用程序的类别 */
version INTEGER /* 用于描述版本号(以迭代次数统计) */
);
可以结合业务场景设计枚举类型,促进数据的可理解性
一般而言,许多的应用对于分类的工作,将会使用“INTEGER”(整数)结合注释来加以完成
(如我们写出注释:/* 1. beta 2. alpha 3. release 4. production */)。
这种方法的好处在于,效率较高(因为对于整数的增删查改是一项非常基本的数据库管理操作,但是坏处在于,因为整数终究是数字,没有和具体的业务直接联系在一起,因此单独提取出来,很难让人理解其具体内涵。
而枚举类型,正如读者所见,可以直接联系业务场景用以分类,进而使得其存储的数据的可理解性较好,强化了协作能力,但是因为其通用性和效率不如整数类型,所以在许多应用中,难以寻得其踪迹。
之后,我们可以尝试向 application_list 数据表写入一些应用程序数据:
/* 所有的 LOGO URL 我们均设定为 NULL */
/* 主题色采用 HEX 代码 */
INSERT INTO application_list VALUES ('VSCODE', '微软', '一款跨平台的通用编辑器', NULL, '#0066b8', '2024-7-3', 'release', x'ea1445c'::INTEGER);
INSERT INTO application_list VALUES ('AtomGit', '开放原子开源基金会', '基于 Git 的源代码托管服务', NULL, '#117efb', '2024-4-25', 'release', '1' /* 第一个正式版本 */);
INSERT INTO application_list VALUES ('The Battle for Wesnoth', 'Wesnoth Community', '一款跨平台战棋游戏', NULL, '#ecc874', '2024-6-30', 'release', '18');
INSERT INTO application_list VALUES ('PostGIS', 'PostGIS PSC & OSGeo', '一款 PostgreSQL 时空数据库拓展', NULL, '#6e8faf', '2024-7-6', 'alpha', 3.5::INTEGER);
INSERT INTO application_list VALUES ('Vim', 'Vim Community', 'Vi 编辑器增强版本', NULL, '#007f00', '2024-7-2', 'release', 9.1::INTEGER);
INSERT INTO application_list VALUES ('Emacs', 'GNU', 'Linux 平台经典编辑器', NULL, '#7f5ab6', '2024-6-22', 'release', 29.4::INTEGER);
:: 运算符可以实现数据类型的转换
在此处插入代码的场景下,我们使用 :: 表达式将十六进制数字字符串(x 标识了数据的基本情况),转换为 INTEGER 类型(以及其它许多的小写版本号等)。
类似的转换类型表达式还有 CAST 表达式,因此上述类型转换��还可以书写为:
CAST (x'ea1445c' AS INTEGER)
使用 CREATE CAST 可以使得 PostgreSQL 能够了解如何对我们自定义的数据类型展开转化工作。
之后,我们可以使用 GROUP BY 语句对数据列进行分组,结合我们之前学习过的聚合函数与窗口函数,展开一定的统计工作。
GROUP BY 语句将会删除数据重复的数据列
分组语句所做的事情实际上就是分类,而众所周知,类别只能有一个存在。所以 GROUP BY 将会展开去重的工作。
按照软件类别分组统计其数目
假定我们想要查看各类型软件的数目,则可以执行如下的语句:
SELECT type, count(type) FROM application_list GROUP BY type;
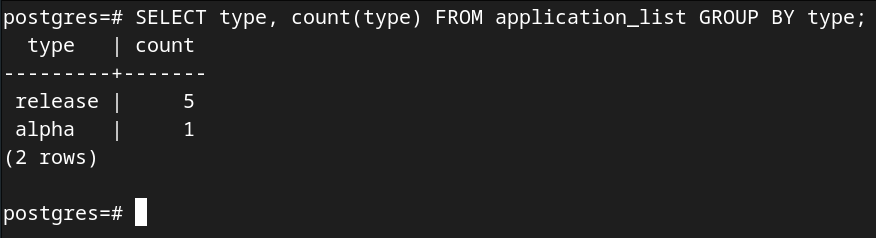
可以发现,当前记录中,release 版本的软件有5款,而 alpha 版本的软件则只有一款。
这种先分组再使用聚合函数或者窗口函数加以统计的做法,就是 GROUP BY 语句的基本作风,接下来,让我们把目光聚焦于 ORDER BY 语句上面,它是一种用于排序用的语句。
ORDER BY 语句简介
统计各类软件的下载数目,由此为用户提供服务同样也是很多应用商店程序的重要工作内容,如 Flathub 程序中,将会根据下载量的多少或者日期的新旧进行排序,进而为用户推荐 “Popular”(最流行的),“New”(新推出),“Updated”(最新更新的) 软件,出于简化的目的,我们这里将选择 “Popular” 和 “New” 两种场景展开讨论。
![]()
这里,我们首先创建一张数据表,用于描述应用:
CREATE TABLE application_list (
name TEXT, /* 应用程序名称 */
description TEXT, /* 用于描述应用程序的作用 */
logo_url TEXT, /* 用于存储应用程序 LOGO 的 URL */
publish_date DATE, /* 用于描述应用程序的发版日期 */
download_counts INTEGER /* 下载次数统计 */
);
之后,我们可以尝试插入一些数据:
INSERT INTO application_list VALUES ('VSCODE', 'Code Editing. Redefined', NULL, '2024-7-3', 6000000);
INSERT INTO application_list VALUES ('Vim', 'Vim - Vi Improved', NULL, '2024-7-2', 8000000);
INSERT INTO application_list VALUES ('Sublime Text', 'Text Editing, Done Right', NULL, '2024-11-24', 5000000);
INSERT INTO application_list VALUES ('Emacs', 'An extensible, customizable, free/libre text editor — and more', NULL, '2024-6-22', 4500000);
INSERT INTO application_list VALUES ('Atom Editor', 'The hackable text editor', NULL, '2022-12-15', 800000);
之后,我们可以尝试对 application_list 展开一个排序:
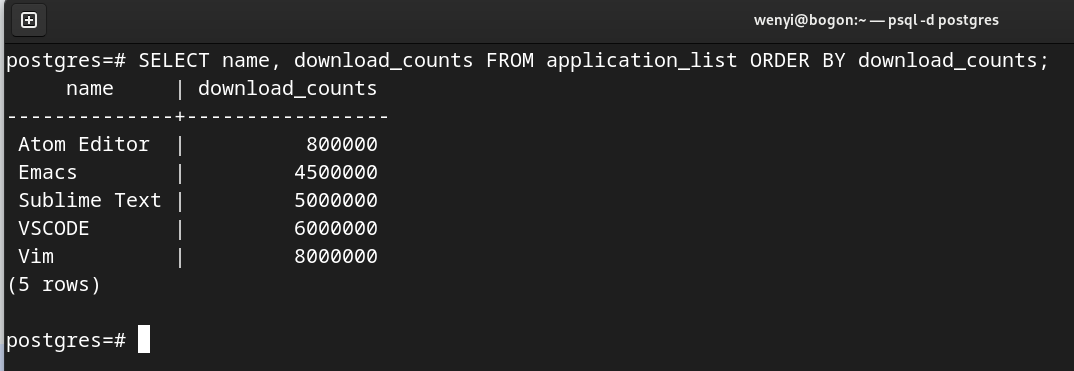
SELECT name, download_counts FROM application_list ORDER BY download_counts;
加入 DESC 指令可以使得以由小到大的方式来排序:
SELECT name, download_counts FROM application_list ORDER BY download_counts DESC;
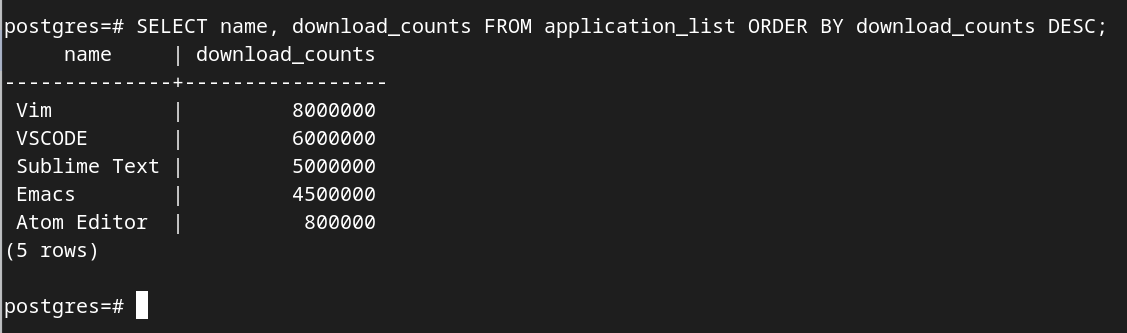
这样,我们也就得到了 “popular” 所需要的数据(流行度排序的本质就是下载量的比较)
我们同样可以对日期展开排序:
SELECT name, publish_date FROM application_list ORDER BY publish_date DESC;
SELECT name, publish_date FROM application_list ORDER BY publish_date;
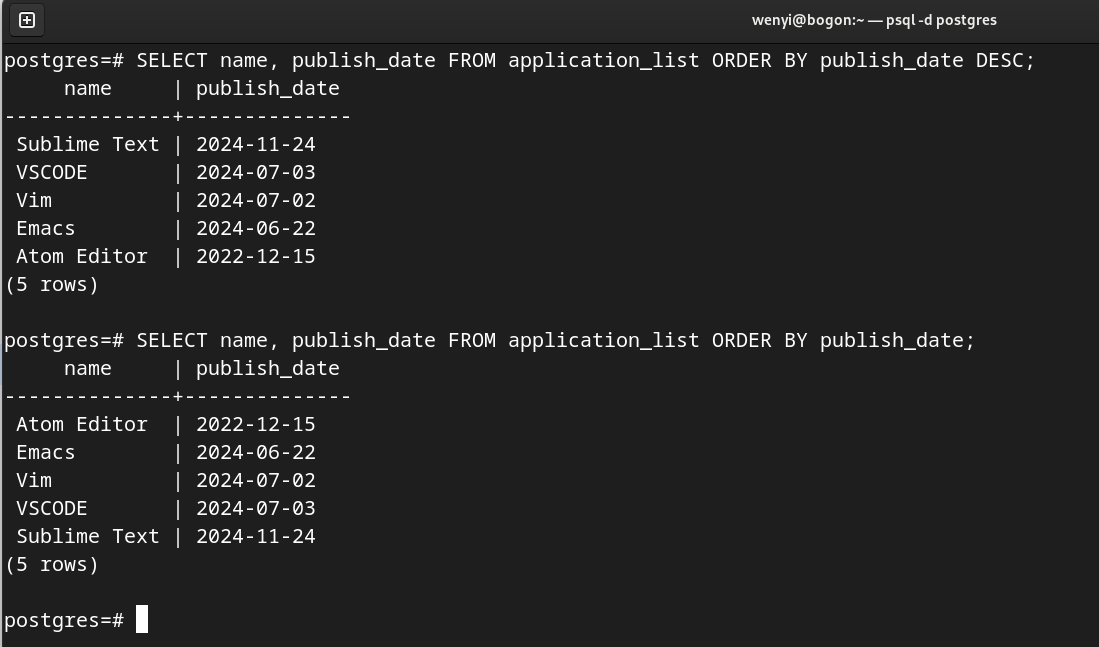
这样我们也就可以向用户推荐最“New”版本的软件了。